XPath est un langage de requête conçu pour extraire des informations à partir de documents XML. La première version, XPath 1.0, est ratifiée par le World Wide Web Consortium (W3C) en 1999. À partir de 2007, le langage connaît des évolutions importantes dans sa syntaxe, il devient ainsi plus complet par rapport à la version initiale.

Qu'est-ce que XPath ?
XPath est un langage de requête conçu pour naviguer et extraire des données efficacement à partir de documents XML. XPath est généralement intégré dans un langage hôte comme Python, C# ou JavaScript.
À quoi sert XPath ?
XPath est un langage simple utilisé pour faire des recherches dans des documents de type XML ou comme outil dans d'autres technologies comme XSLT ou XQuery.
Les expressions XPath s'étendent aux fichiers HTML, permettant ainsi d'extraire des données sur les sites internet avec le web scraping. La localisation des éléments est effectuée sous la forme de chemins, à la manière d'un répertoire de fichiers. Il convient de noter que pour traiter des chaînes de données n'ayant pas d'arborescence spécifique, les expressions régulières (REGEX) sont plus adaptées.
Les principes de XPath
1 - La syntaxe
La syntaxe de XPath correspond aux expressions utilisées pour sélectionner des nœuds. Ces expressions sont essentielles pour spécifier les chemins empruntés dans les documents XML.
Les expressions couramment utilisées sont listées ci-dessous :
| nodename |
Sélectionner les nœuds avec le nom « nodename » (à remplacer par le nom du nœud recherché) |
| / |
Sélectionner le nœud racine |
| // |
Sélectionner les nœuds dans le document, peu importe leur position |
| . |
Sélectionner le nœud actif |
| .. |
Sélectionner le nœud parent du nœud actif |
| @ |
Sélectionner les nœuds de type attribut |
| :: |
Spécifier un axe |
| * |
Sélectionner les nœuds contextuels de type élément |
L'utilisation du caractère
/ en début d'expression spécifie le contexte actuel comme étant la racine du document, c'est une expression absolue. À l'inverse, une expression ne commençant pas par le caractère / est une expression relative à un contexte.
Pour mieux comprendre la syntaxe des expressions XPath, il est préférable de s'appuyer sur des exemples concrets. Ainsi, l'exemple suivant de fichier XML va faire office de fil conducteur pour illustrer l'ensemble des principes de XPath. Ce fichier XML rassemble des informations sur des paires de chaussettes et des bonnets (les tailles, les prix et les matières) rangés dans plusieurs tiroirs nommés t1 et t2.
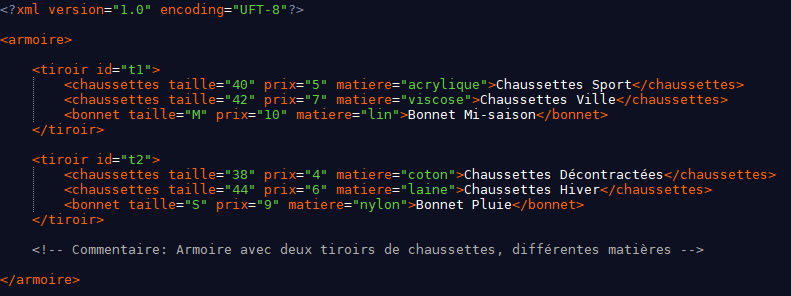
Par exemple, l'expression /armoire renvoie à toutes les valeurs présentes dans l'armoire à la racine. Ici, les données retournées sont Chaussettes Sport, Chaussettes Ville, Chaussettes décontractées, Chaussettes Hiver, Bonnet Mi-saison, Bonnet Pluie.
L'expression /armoire/tiroir/chaussettes sélectionne toutes les valeurs chaussettes présentes dans chaque tiroir.
L'expression //chaussettes/@taille sélectionne l'attribut taille de toutes les valeurs chaussettes présentes n'importe où dans le document XML. Ici, les valeurs retournées sont 40, 42, 38, 44.
2 - Les nœuds
Les documents XML sont traités comme des arbres de nœuds. Il existe sept types de nœuds : les éléments, les attributs, les nœuds de texte, les espaces de noms, les instructions de traitement, les commentaires et le nœud racine.
Pour sélectionner le type de nœud souhaité, il est nécessaire d'utiliser un filtre, aussi appelé test de nœud. Il est important de noter que les attributs et les espaces de nom sont sélectionnés à partir d'axes.
Les tests de nœud les plus utilisés sont :
| node() |
Correspond à n'importe quel nœud |
| text() |
Correspond à n'importe quel nœud de texte |
| comment() |
Correspond à n'importe quel nœud de commentaire |
| * |
Correspond à n'importe quel nœud élément |
| processing-instruction('cible') |
Correspond aux nœuds d'instructions de traitement |
En se basant sur l'exemple du fichier XML précédent, le test de nœud //text() sélectionne toutes les valeurs textuelles présentes dans le document, peu importe la position. Ici les valeurs retournées sont Chaussettes Sport, Chaussettes Ville, Chaussettes décontractées, Chaussettes Hiver, Bonnet Mi-saison, Bonnet Pluie.
Le test de nœud //comment() sélectionne tous les commentaires du document, ici Commentaire : Armoire avec deux tiroirs de chaussettes, différentes matières.
3 - Les axes
Les axes représentent les relations généalogiques entre les nœuds. Ils sont utilisés pour localiser et sélectionner des nœuds relatifs aux nœuds contextuels, que ce soit des nœuds parents, enfants ou frères.
Les axes couramment utilisés sont :
| self |
Sélectionner le nœud actif |
| child |
Sélectionner les nœuds enfants du nœud actif |
| parent |
Sélectionner le nœud parent du nœud actif |
| ancestor, ancestor-or-self |
Sélectionner les nœuds ancêtres du nœud actif |
| descendant, descendant-or-self |
Sélectionner les nœuds descendants du nœud actif |
| preceding |
Sélectionner les nœuds qui précèdent le nœud actif |
| following |
Sélectionner les nœuds qui suivent le nœud actif |
| preceding-sibling |
Sélectionner les nœuds frères qui précèdent le nœud actif |
| following-sibling |
Sélectionner les nœuds frères qui suivent le nœud actif |
| namespace |
Sélectionner les nœuds de type espace de nom |
| attribute |
Sélectionner les nœuds de type attribut |
Voici quelques exemples concrets basés sur le fichier XML précédent :
L'expression /armoire/descendant::chaussettes sélectionne tous les descendants chaussettes de l'élément racine armoire, ici Chaussettes Sport, Chaussettes Ville, Chaussettes Décontractées, Chaussettes Hiver.
L'expression //chaussettes/following-sibling::bonnet sélectionne les nœuds frères bonnet qui suivent les nœuds chaussettes, ici Bonnet Mi-saison, Bonnet Pluie.
4 - Les prédicats
L'utilisation des axes ne suffit pas à spécifier la position d'un nœud, afin d'obtenir un résultat plus précis, il est conseillé d'utiliser les prédicats. Les prédicats permettent de filtrer les nœuds sélectionnés par les axes et les tests de nœud. Les prédicats sont intégrés dans l'expression à l'aide de crochets []. Les valeurs indiquées dans les prédicats correspondent aux nœuds de type attribut.
Par exemple, l'expression //tiroir[@id='t1']/chaussettes[1]/following-sibling::chaussettes sélectionne les nœuds frères qui suivent la première paire de chaussettes présente dans le tiroir ayant pour identifiant t1. Ici, le résultat est Chaussettes Ville.
L'expression //chaussettes[@taille="42"]/@matiere renvoie vers l'attribut matiere des paires de chaussettes ayant pour taille 42. Ici, le résultat est Viscose.
Où trouver le chemin XPath d'un élément dans une page web ?
Trouver le chemin XPath d'un élément dans une page web est une action simple. Pour ce faire, il est nécessaire de suivre les étapes suivantes :
1 - Ouvrir le navigateur de recherche (Google ou Firefox) et accéder à une page de site web.
2 - Appuyer sur F12 ou utiliser les raccourcis CTRL + SHIFT + I pour Firefox et CTRL + SHIT + J pour Google Chrome. Cette action permet d'ouvrir les outils de développement.
3 - Cliquer sur le bouton « sélectionner un élément de la page » situé en haut à gauche des outils de développement.
4 - Parcourir la page web pour sélectionner l'élément souhaité.
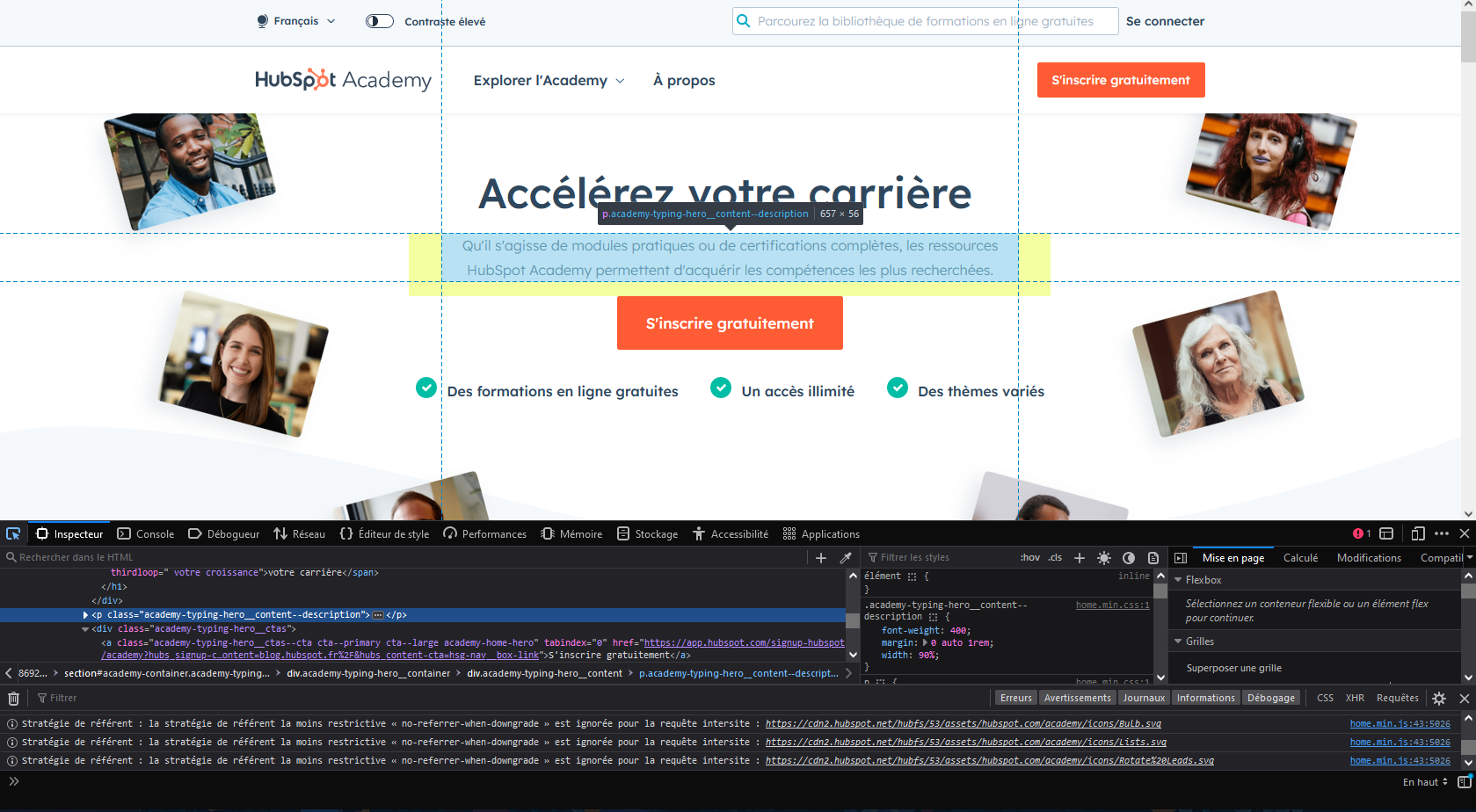
5 - Localiser l'élément dans le code source de la page web. Ce dernier est surligné dans l'outil inspecteur.
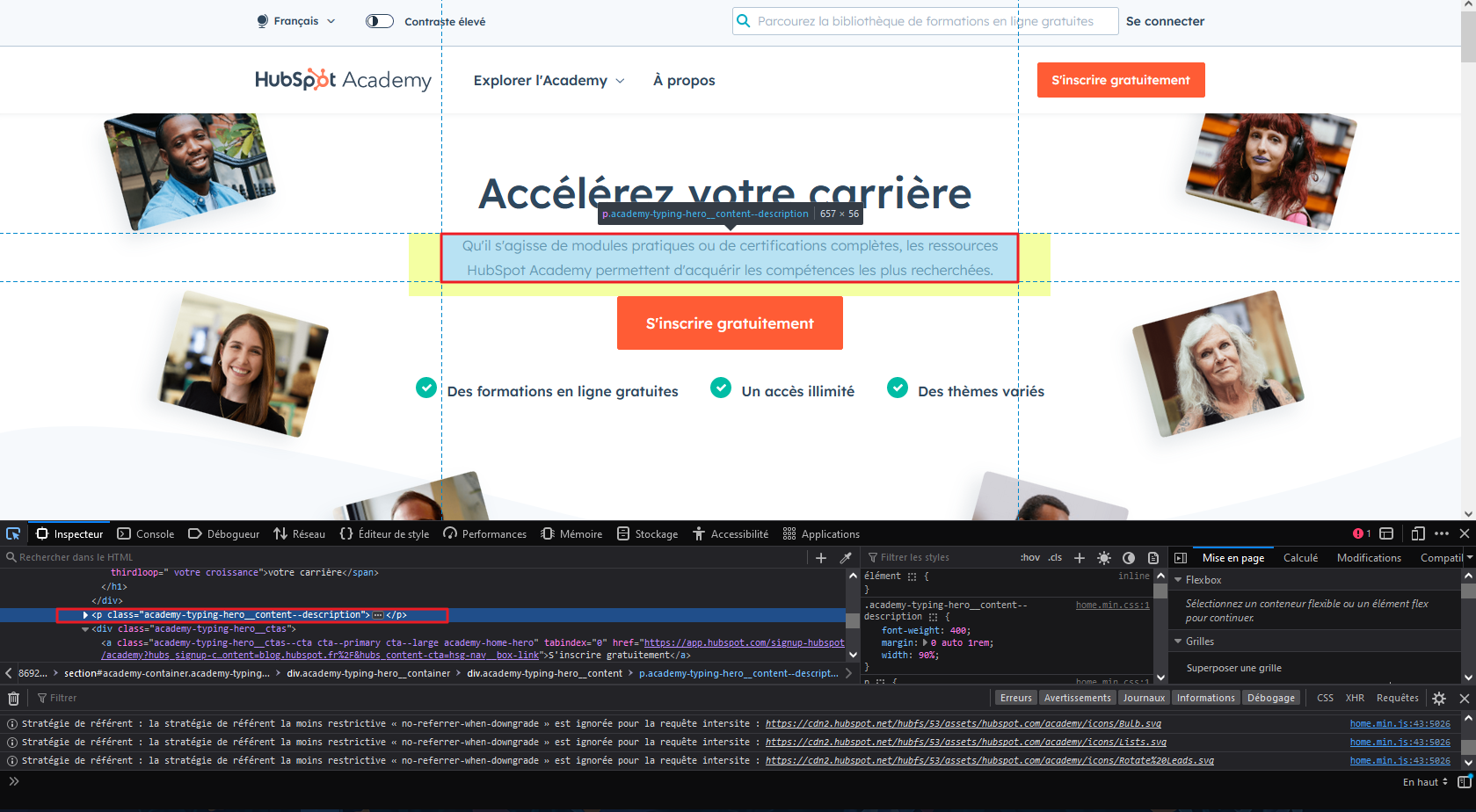
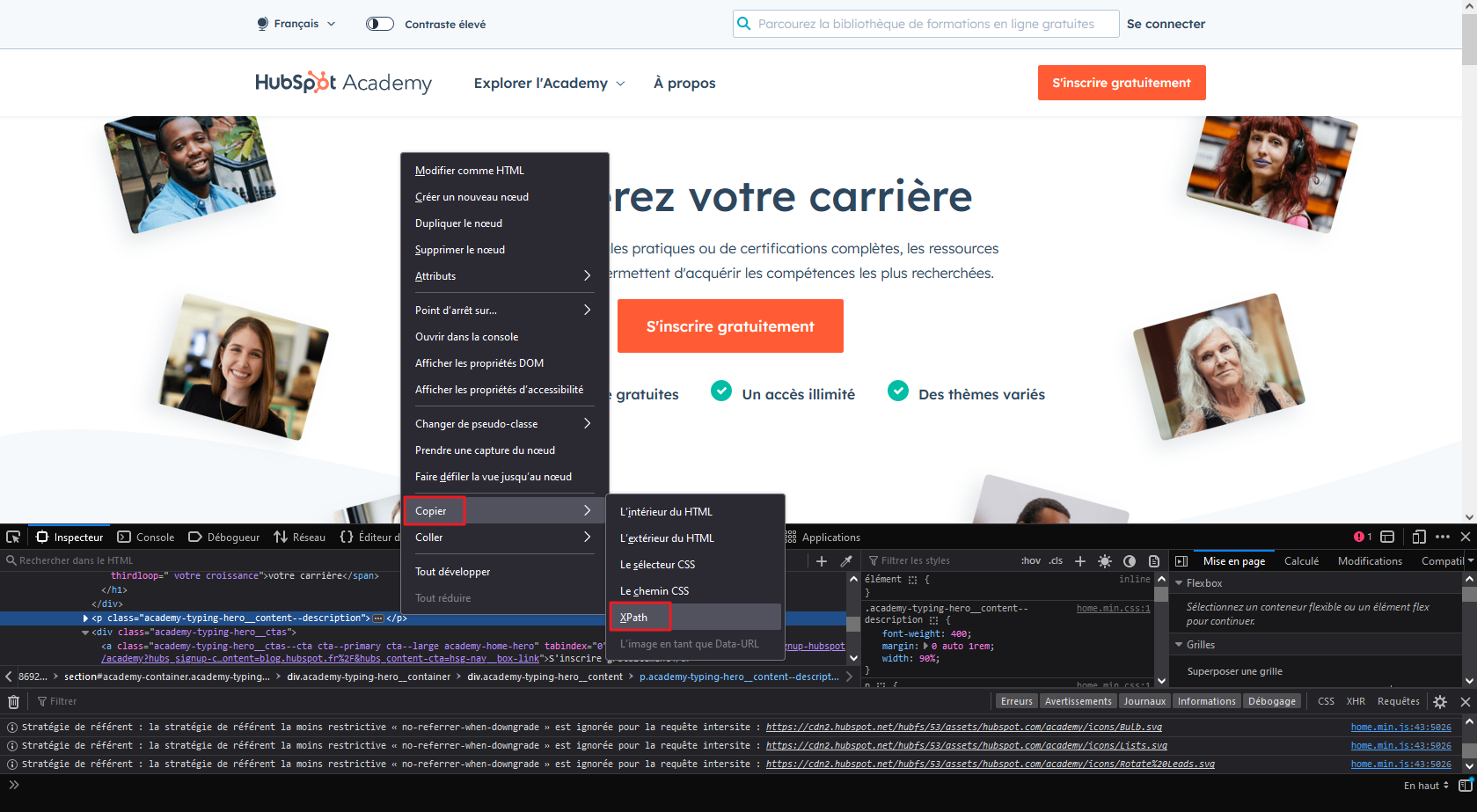
6 - Réaliser un clic droit sur la ligne de code puis sélectionner l'option copier pour choisir XPath.
7 - Intégrer le chemin XPath dans divers outils de développement web.
L'utilisation des expressions XPath dans le développement web
1 - XPath pour le web scraping
XPath est un langage populaire souvent utilisé pour le web scraping. Le web scraping est une pratique consistant à extraire les données d'un site web par le biais d'un script ou d'un programme. Des outils comme Beautiful Soup ou Scrapy supportent le langage XPath.
L'exemple ci-dessous représente une structure simple de page web. Pour extraire à la fois les prix et les noms des produits en utilisant XPath, il faut identifier des chemins XPath distincts pour les deux informations.
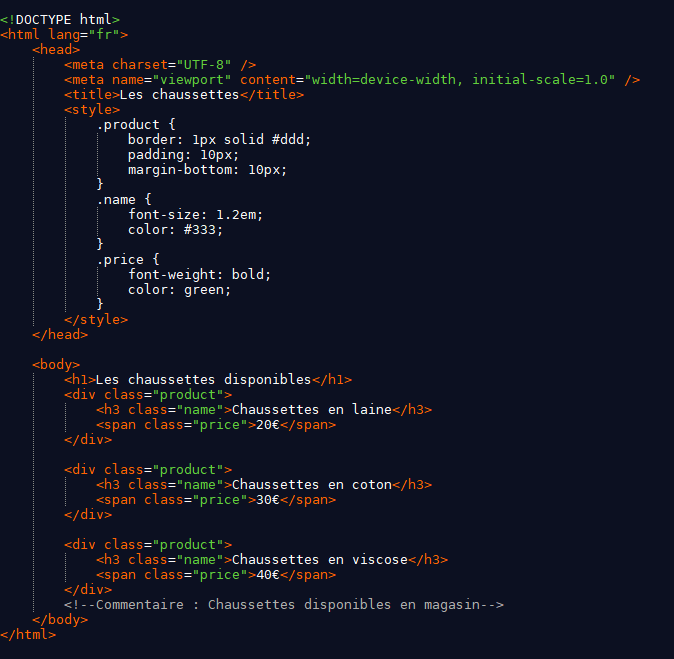
Ici, le chemin XPath pour extraire les noms des produits est //div[@class='product']/h3[@class='name'], celui pour extraire les prix est //div[@class='product']/span[@class='price']. En intégrant ces chemins dans un script, il est possible d'agréger les résultats obtenus pour ressortir les noms et les prix de tous les produits indiqués sur la page HTML.
2 - XPath pour l'automatisation de test
Les chemins XPath sont également très efficaces lorsqu'ils sont intégrés dans des frameworks de tests comme Selenium. L'outil Selenium est conçu pour interagir avec les navigateurs web à la manière d'un utilisateur.
Dans ce contexte, XPath peut être utilisé pour identifier des éléments spécifiques de la page web, comme les barres de recherche et de navigation. Par exemple, pour localiser une barre de recherche dont l'attribut id défini est search-box, le chemin XPath approprié est //*[@id='search-box'].
En intégrant ce chemin dans Selenium, il est possible d'automatiser les scénarios de tests et de vérifier si les éléments clés de l'interface sont fonctionnels afin d'optimiser le site web.
Pour aller plus loin, découvrez les opportunités d'affaires liées aux évolutions du web en téléchargeant le guide et la checklist du web 3.0, ou découvrez le logiciel marketing de HubSpot.

XPath expliqué : comment extraire des données et naviguer dans des documents XML
GUIDE GRATUIT : WEB 3.0
Révolutionnez votre stratégie marketing digital pour rester pertinent dans la nouvelle version d'internet, le web 3.0.
Télécharger gratuitementMis à jour :
XPath est un langage de requête conçu pour extraire des informations à partir de documents XML. La première version, XPath 1.0, est ratifiée par le World Wide Web Consortium (W3C) en 1999. À partir de 2007, le langage connaît des évolutions importantes dans sa syntaxe, il devient ainsi plus complet par rapport à la version initiale.
Qu'est-ce que XPath ?
XPath est un langage de requête conçu pour naviguer et extraire des données efficacement à partir de documents XML. XPath est généralement intégré dans un langage hôte comme Python, C# ou JavaScript.
À quoi sert XPath ?
XPath est un langage simple utilisé pour faire des recherches dans des documents de type XML ou comme outil dans d'autres technologies comme XSLT ou XQuery.
Les expressions XPath s'étendent aux fichiers HTML, permettant ainsi d'extraire des données sur les sites internet avec le web scraping. La localisation des éléments est effectuée sous la forme de chemins, à la manière d'un répertoire de fichiers. Il convient de noter que pour traiter des chaînes de données n'ayant pas d'arborescence spécifique, les expressions régulières (REGEX) sont plus adaptées.
Les principes de XPath
1 - La syntaxe
La syntaxe de XPath correspond aux expressions utilisées pour sélectionner des nœuds. Ces expressions sont essentielles pour spécifier les chemins empruntés dans les documents XML.
Les expressions couramment utilisées sont listées ci-dessous :
L'utilisation du caractère
/ en début d'expression spécifie le contexte actuel comme étant la racine du document, c'est une expression absolue. À l'inverse, une expression ne commençant pas par le caractère / est une expression relative à un contexte.Pour mieux comprendre la syntaxe des expressions XPath, il est préférable de s'appuyer sur des exemples concrets. Ainsi, l'exemple suivant de fichier XML va faire office de fil conducteur pour illustrer l'ensemble des principes de XPath. Ce fichier XML rassemble des informations sur des paires de chaussettes et des bonnets (les tailles, les prix et les matières) rangés dans plusieurs tiroirs nommés t1 et t2.
Par exemple, l'expression /armoire renvoie à toutes les valeurs présentes dans l'armoire à la racine. Ici, les données retournées sont Chaussettes Sport, Chaussettes Ville, Chaussettes décontractées, Chaussettes Hiver, Bonnet Mi-saison, Bonnet Pluie.
L'expression /armoire/tiroir/chaussettes sélectionne toutes les valeurs chaussettes présentes dans chaque tiroir.
L'expression //chaussettes/@taille sélectionne l'attribut taille de toutes les valeurs chaussettes présentes n'importe où dans le document XML. Ici, les valeurs retournées sont 40, 42, 38, 44.
2 - Les nœuds
Les documents XML sont traités comme des arbres de nœuds. Il existe sept types de nœuds : les éléments, les attributs, les nœuds de texte, les espaces de noms, les instructions de traitement, les commentaires et le nœud racine.
Pour sélectionner le type de nœud souhaité, il est nécessaire d'utiliser un filtre, aussi appelé test de nœud. Il est important de noter que les attributs et les espaces de nom sont sélectionnés à partir d'axes.
Les tests de nœud les plus utilisés sont :
En se basant sur l'exemple du fichier XML précédent, le test de nœud //text() sélectionne toutes les valeurs textuelles présentes dans le document, peu importe la position. Ici les valeurs retournées sont Chaussettes Sport, Chaussettes Ville, Chaussettes décontractées, Chaussettes Hiver, Bonnet Mi-saison, Bonnet Pluie.
Le test de nœud //comment() sélectionne tous les commentaires du document, ici Commentaire : Armoire avec deux tiroirs de chaussettes, différentes matières.
3 - Les axes
Les axes représentent les relations généalogiques entre les nœuds. Ils sont utilisés pour localiser et sélectionner des nœuds relatifs aux nœuds contextuels, que ce soit des nœuds parents, enfants ou frères.
Les axes couramment utilisés sont :
Voici quelques exemples concrets basés sur le fichier XML précédent :
L'expression /armoire/descendant::chaussettes sélectionne tous les descendants chaussettes de l'élément racine armoire, ici Chaussettes Sport, Chaussettes Ville, Chaussettes Décontractées, Chaussettes Hiver.
L'expression //chaussettes/following-sibling::bonnet sélectionne les nœuds frères bonnet qui suivent les nœuds chaussettes, ici Bonnet Mi-saison, Bonnet Pluie.
4 - Les prédicats
L'utilisation des axes ne suffit pas à spécifier la position d'un nœud, afin d'obtenir un résultat plus précis, il est conseillé d'utiliser les prédicats. Les prédicats permettent de filtrer les nœuds sélectionnés par les axes et les tests de nœud. Les prédicats sont intégrés dans l'expression à l'aide de crochets []. Les valeurs indiquées dans les prédicats correspondent aux nœuds de type attribut.
Par exemple, l'expression //tiroir[@id='t1']/chaussettes[1]/following-sibling::chaussettes sélectionne les nœuds frères qui suivent la première paire de chaussettes présente dans le tiroir ayant pour identifiant t1. Ici, le résultat est Chaussettes Ville.
L'expression //chaussettes[@taille="42"]/@matiere renvoie vers l'attribut matiere des paires de chaussettes ayant pour taille 42. Ici, le résultat est Viscose.
Où trouver le chemin XPath d'un élément dans une page web ?
Trouver le chemin XPath d'un élément dans une page web est une action simple. Pour ce faire, il est nécessaire de suivre les étapes suivantes :
1 - Ouvrir le navigateur de recherche (Google ou Firefox) et accéder à une page de site web.
2 - Appuyer sur F12 ou utiliser les raccourcis CTRL + SHIFT + I pour Firefox et CTRL + SHIT + J pour Google Chrome. Cette action permet d'ouvrir les outils de développement.
3 - Cliquer sur le bouton « sélectionner un élément de la page » situé en haut à gauche des outils de développement.
4 - Parcourir la page web pour sélectionner l'élément souhaité.
5 - Localiser l'élément dans le code source de la page web. Ce dernier est surligné dans l'outil inspecteur.
6 - Réaliser un clic droit sur la ligne de code puis sélectionner l'option copier pour choisir XPath.
7 - Intégrer le chemin XPath dans divers outils de développement web.
L'utilisation des expressions XPath dans le développement web
1 - XPath pour le web scraping
XPath est un langage populaire souvent utilisé pour le web scraping. Le web scraping est une pratique consistant à extraire les données d'un site web par le biais d'un script ou d'un programme. Des outils comme Beautiful Soup ou Scrapy supportent le langage XPath.
L'exemple ci-dessous représente une structure simple de page web. Pour extraire à la fois les prix et les noms des produits en utilisant XPath, il faut identifier des chemins XPath distincts pour les deux informations.
Ici, le chemin XPath pour extraire les noms des produits est //div[@class='product']/h3[@class='name'], celui pour extraire les prix est //div[@class='product']/span[@class='price']. En intégrant ces chemins dans un script, il est possible d'agréger les résultats obtenus pour ressortir les noms et les prix de tous les produits indiqués sur la page HTML.
2 - XPath pour l'automatisation de test
Les chemins XPath sont également très efficaces lorsqu'ils sont intégrés dans des frameworks de tests comme Selenium. L'outil Selenium est conçu pour interagir avec les navigateurs web à la manière d'un utilisateur.
Dans ce contexte, XPath peut être utilisé pour identifier des éléments spécifiques de la page web, comme les barres de recherche et de navigation. Par exemple, pour localiser une barre de recherche dont l'attribut id défini est search-box, le chemin XPath approprié est //*[@id='search-box'].
En intégrant ce chemin dans Selenium, il est possible d'automatiser les scénarios de tests et de vérifier si les éléments clés de l'interface sont fonctionnels afin d'optimiser le site web.
Pour aller plus loin, découvrez les opportunités d'affaires liées aux évolutions du web en téléchargeant le guide et la checklist du web 3.0, ou découvrez le logiciel marketing de HubSpot.
Développement Web
Partager cet article sur les réseaux sociaux
Articles recommandés
Pop-up site web : définition et exemples pour augmenter les conversions
Apprendre à coder en 2026 : comment bien débuter + ressources gratuites
Code source d'une page web : explications, structure et création
Webhook : fonctionnement, configuration et cas d'usage pour automatiser vos processus
Fichier JSON : qu'est-ce que c'est et comment l'utiliser ?
URI vs URL : quelle est la différence ?
Langage de programmation : 10 langages les plus courants (et leur utilisation)
WYSIWYG : définition, utilisation et exemples
Fichier XML : qu'est-ce que c'est et comment l'ouvrir ?
Checklist d'onboarding IT : préparer ses nouveaux collaborateurs avec efficacité